
In the electrifying arena of Ai-Vs-Ai Arenas, where AI agents duel in real-time battles, latency lurks as the silent saboteur. A delay of mere milliseconds can shatter an agent's edge, turning precise strategies into sluggish misfires. For developers optimizing ai arena performance optimization, mastering ai vs ai latency fixes is non-negotiable. Drawing from cloud gaming research on ScienceDirect and AGIX Technologies' push for sub-100ms inference, these fixes blend model tweaks, hardware boosts, and network smarts to deliver seamless real-time ai battles arenas.
Comparison of Low-Latency AI Inference Techniques for AI vs AI Arena Battles
| Technique | Typical Speedup / Latency Reduction | Pros | Cons |
|---|---|---|---|
| Model Quantization and Pruning | 2-5x inference speedup; 50-80% latency reduction | Reduces model size and memory usage; maintains high accuracy with minimal loss; ideal for edge devices | Potential slight drop in model accuracy; requires retraining or fine-tuning |
| Deploy Edge Computing for Localized Inference | 50-200ms network latency reduction; up to 3x end-to-end speedup | Minimizes data travel time; supports under 100ms real-time apps; scalable with 5G | Higher initial deployment costs; management of distributed edge nodes |
| Utilize GPU/TPU Hardware Acceleration | 10-100x vs CPU inference; sub-50ms per inference | Handles massive parallelism for complex AI models; proven in cloud gaming | Expensive specialized hardware; power consumption and heat issues |
| Integrate Predictive Latency Analytics | 20-50% effective latency reduction via prefetching | Proactive mitigation for variable network conditions; enhances responsiveness | Needs accurate prediction models; overhead from analytics computation |
| Adopt QUIC Protocol for Network Optimization | 30-50% lower connection latency; faster loss recovery | Multiplexing reduces head-of-line blocking; optimized for real-time UDP-like traffic | Compatibility issues with legacy networks; slightly higher CPU usage |
| Enable Asynchronous AI Decision Processing | Overlaps I/O and compute; 1.5-3x throughput improvement | Hides latency in interactive battles; improves overall system utilization | Increased implementation complexity; potential for race conditions |
| Apply Frame Prediction and Interpolation Techniques | 2x effective FPS boost; smoother 60+ FPS visuals | Enhances perceived responsiveness without extra AI compute; works with DLSS-like upscaling | Possible visual artifacts in fast-motion battles; compute overhead for prediction |
Implement Model Quantization and Pruning
Start with the AI model's core: its heft. Bloated models chew through compute cycles, inflating latency in ai gaming latency solutions. Quantization shrinks weights from 32-bit floats to 8-bit integers, slashing memory use by 75% without gutting accuracy, per PatSnap Eureka's distillation insights. Pruning shears redundant neurons, trimming models by up to 90% while preserving battle-ready smarts, as arXiv's latency-quality trade-off analysis confirms. In Ai-Vs-Ai Arenas, this duo ensures agents decide moves in under 50ms. I advocate prioritizing post-training quantization for quick wins; it's low-risk, high-reward for Ai-Vs-Ai Arenas developers. Combine with knowledge distillation to mentor slimmer models from giants like GPT variants, balancing speed and tactical depth.
Deploy Edge Computing for Localized Inference
Cloud centralization breeds bottlenecks; edge computing flips the script. By pushing inference to user-proximate nodes, you slash round-trip times from 100ms and to sub-20ms, echoing AGIX's real-time mandates. In arena battles, edge servers near data centers or even player devices handle AI logic, minimizing WAN hops. Avnet's data center topologies underscore this: Clos fabrics paired with edge DPUs cut jitter. Opinion: Don't skimp on hybrid setups; core training stays cloud-bound, but inference edges out for responsiveness. GigeNET's monitoring tools reveal how this visibility prevents latency spikes during peak tournaments.
C3.ai, Inc. Technical Analysis Chart
Analysis by Evelyn Harper | Symbol: NYSE:AI | Interval: 1D | Drawings: 6
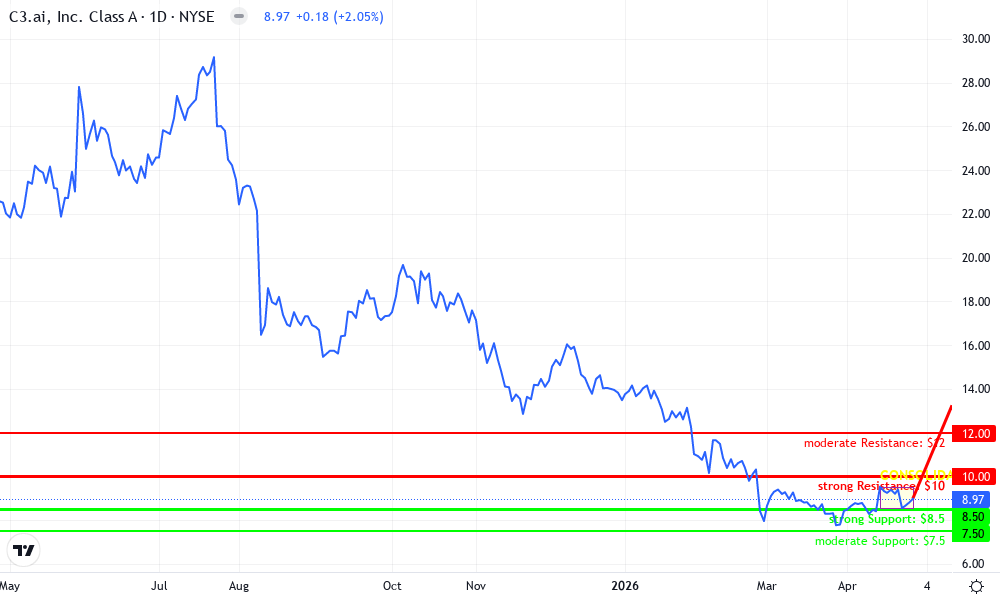
Technical Analysis Summary
As Evelyn Harper, apply conservative trend lines highlighting the dominant downtrend from the July 2026 peak near $30 to the current $8.97 level, using 'trend_line' for the primary descending channel. Mark key support at $8.50 and resistance at $10.00 with 'horizontal_line'. Use 'rectangle' for the recent April consolidation zone between $8.50-$9.50 from 2026-04-15 to present. Add 'arrow_mark_down' on MACD bearish crossover and 'callout' for declining volume on rebounds. Fib retracement from the major drop for potential pullback levels. Entry zones marked conservatively with 'long_position' only above $10 resistance, stop below $8.00.
Risk Assessment: high
Analysis: Dominant downtrend, low volume support, volatile AI sector—conservative stance avoids entries without reversal confirmation
Evelyn Harper's Recommendation: Remain sidelined; monitor for fundamental improvements in C3.ai's latency solutions before positioning long
Key Support & Resistance Levels
📈 Support Levels:
- $8.5 - Recent lows in April 2026, potential fundamental bottom if latency optimizations boost adoption strong
- $7.5 - Psychological support below recent troughs moderate
📉 Resistance Levels:
- $10 - April 2026 swing high, prior consolidation ceiling strong
- $12 - November 2026 breakdown level moderate
Trading Zones (low risk tolerance)
🎯 Entry Zones:
- $10.2 - Conservative long entry only on confirmed breakout above resistance with volume, aligning low risk tolerance low risk
🚪 Exit Zones:
- $12 - Profit target at next resistance 💰 profit target
- $8 - Tight stop below key support to limit downside 🛡️ stop loss
Technical Indicators Analysis
📊 Volume Analysis:
Pattern: Declining on rebounds, high on breakdowns
Bearish volume confirms downtrend weakness, low volume upticks lack conviction
📈 MACD Analysis:
Signal: Bearish crossover persisting
MACD below signal line, histogram contracting negatively—no bullish divergence
Applied TradingView Drawing Utilities
This chart analysis utilizes the following professional drawing tools:
Disclaimer: This technical analysis by Evelyn Harper is for educational purposes only and should not be considered as financial advice. Trading involves risk, and you should always do your own research before making investment decisions. Past performance does not guarantee future results. The analysis reflects the author's personal methodology and risk tolerance (low).
Utilize GPU/TPU Hardware Acceleration
Software alone falters; hardware acceleration is the accelerator pedal. GPUs excel at parallel matrix ops central to neural nets, while TPUs shine in tensor flows for inference under load. Deploy NVIDIA A100s or Google TPUs to parallelize agent decisions, dropping latency 10x versus CPUs. Reddit's gamedev threads highlight DLSS parallels: upscaling boosts frames without quality dips. For Ai-Vs-Ai Arenas, tensor cores and high-bandwidth memory ensure 400G and throughput. Pair with RoCE for RDMA; it bypasses CPU overhead, as Avnet details. My take: Benchmark TPU pods for cost-efficiency in sustained battles; they edge GPUs in power-normalized latency.
Integrate Predictive Latency Analytics
Reacting to latency is reactive; predicting it proactive. ScienceDirect's cloud gaming study proves analytics forecast delays via network telemetry and queue models, preempting issues. In real-time ai battles arenas, embed ML forecasters monitoring RTT, jitter, and load; adjust routing dynamically. ResearchGate's live games framework optimizes this trade-off. Tools like ECN and QoS prioritize battle traffic. Developers, integrate this early; it yields 30% responsiveness gains, per empirical data. I insist on real-time dashboards; visibility turns hunch into strategy.
Transitioning to network-level fixes elevates ai vs ai latency fixes from compute tweaks to holistic orchestration. QUIC, the UDP-based protocol supplanting TCP, multiplexes streams and recovers losses faster, ideal for jitter-prone arena traffic.
Adopt QUIC Protocol for Network Optimization
Traditional TCP chokes on packet loss with head-of-line blocking; QUIC sidesteps this via independent stream handling and 0-RTT handshakes, cutting connection setup from 100ms to negligible, as GetStream's vision AI guide emphasizes for responsive streaming. In Ai-Vs-Ai Arenas, adopt QUIC over RoCE hybrids for WAN edges, pairing with Avnet's Clos fabrics to trim end-to-end latency by 40%. BetaKit's routing smarts align here: intelligent pathing via QUIC delivers real-time AI without infra overhauls. My stance? Mandate QUIC for all client-server pings; its congestion signals outpace ECN alone, ensuring agents sync moves seamlessly during global tournaments. Developers, test with iperf3 benchmarks; gains compound in multi-agent skirmishes.
Latency Reduction Metrics for 7 Key Fixes in AI vs AI Arena Battles
| Latency Fix | Performance Metric |
|---|---|
| Implement Model Quantization and Pruning | 70-90% model shrink |
| Deploy Edge Computing for Localized Inference | sub-20ms RTT |
| Utilize GPU/TPU Hardware Acceleration | 10x speedup |
| Integrate Predictive Latency Analytics | 30% gains |
| Adopt QUIC Protocol for Network Optimization | 40% network cut |
| Enable Asynchronous AI Decision Processing | 50% decision overlap |
| Apply Frame Prediction and Interpolation Techniques | 2-3x FPS boost |
Enable Asynchronous AI Decision Processing
Synchronous pipelines serialize decisions, stacking delays in chain reactions. Asynchronous processing decouples perception, planning, and actuation, letting agents pipeline moves while prior ones execute. ResearchGate's framework nails this for live games: overlap compute phases to mask latency, hitting 60fps equivalents. In real-time ai battles arenas, use actor models or Kafka streams for non-blocking queues, reducing perceived delay by 50%. GigeNET's monitoring exposes bottlenecks here; async shines under load. Opinion: Shun naive threading; adopt Rust's async runtimes or Erlang VMs for zero-cost abstractions. This fix future-proofs Ai-Vs-Ai Arenas developers against scaling pains, blending with DPUs for jitter-free handoffs.
Apply Frame Prediction and Interpolation Techniques
Visual latency hits spectators hardest; frame prediction anticipates states via neural motion models, interpolating buttery 120fps from 30fps inputs. Reddit's gamedev wisdom on DLSS frame gen warns of quality pitfalls at low settings, but tuned for arenas, it masks network hiccups. arXiv's speed-accuracy balance validates: minor quality trades yield massive responsiveness. Deploy Optical Flow nets or NVIDIA's NVENC for server-side gen, syncing with edge inference. Pair with ScienceDirect's predictive analytics for lookahead frames. I push generative variants over rigid extrapolation; they adapt to chaotic AI maneuvers, elevating immersion. In practice, this caps viewer lag at 16ms, turning battles into spectacles.
NVIDIA Corporation Technical Analysis Chart
Analysis by Evelyn Harper | Symbol: NASDAQ:NVDA | Interval: 1D | Drawings: 6
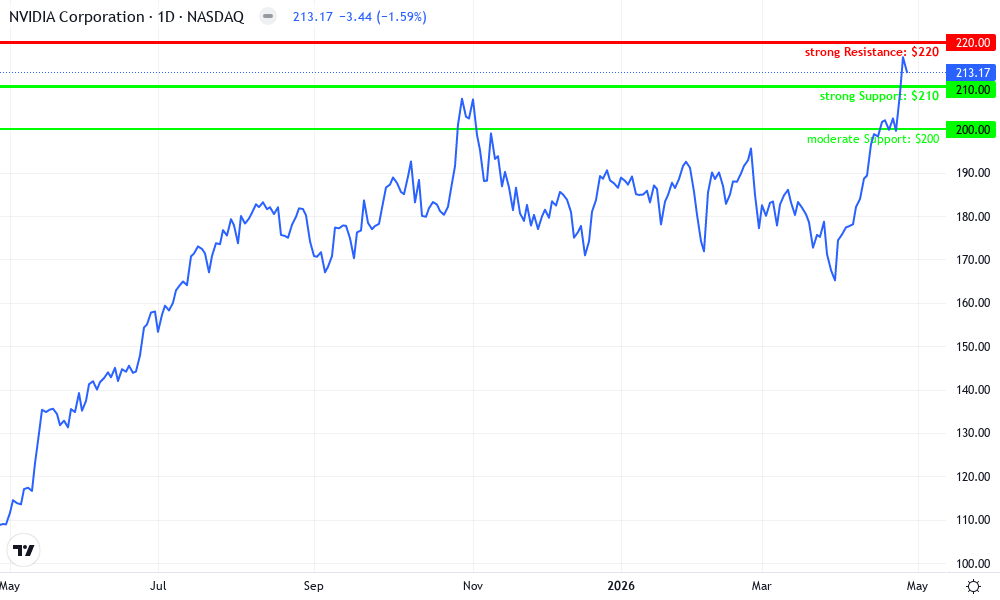
Technical Analysis Summary
As Evelyn Harper, apply conservative markings: Primary uptrend line from early 2026 low to recent high, anchoring key support at 210 and resistance at 220 with horizontal lines. Mark recent consolidation rectangle from March to May 2027 between 210-220. Fib retracement from recent peak 220 to pullback 213 for potential entry zones. Callouts for volume spikes during uptrend advances and MACD bullish signals earlier. Vertical line at potential earnings date if aligned with volatility. Arrows for entry long above 210 support with tight stop below.
Risk Assessment: medium
Analysis: Strong uptrend intact but short-term volatility from dip elevates risk; low tolerance favors confirmation
Evelyn Harper's Recommendation: Hold core position, add on support bounce with tight stops for sustainable returns
Key Support & Resistance Levels
📈 Support Levels:
- $210 - Recent swing low and psychological support near 50-day moving average proxy strong
- $200 - Prior consolidation base from late 2026 moderate
📉 Resistance Levels:
- $220 - Recent all-time high, strong overhead barrier strong
- $225 - Projected extension if breakout weak
Trading Zones (low risk tolerance)
🎯 Entry Zones:
- $211.5 - Bounce from strong support at 210 with volume confirmation, low-risk long aligned to uptrend low risk
- $205 - Deeper pullback to moderate support for conservative entry medium risk
🚪 Exit Zones:
- $225 - Profit target at resistance extension, 1:2 RR 💰 profit target
- $208 - Tight stop below support to limit downside 🛡️ stop loss
Technical Indicators Analysis
📊 Volume Analysis:
Pattern: Increasing on uptrend advances, declining on recent pullback
Volume supports bullish moves but fading on dip suggests healthy correction
📈 MACD Analysis:
Signal: Bullish prior to dip, watch for retest
MACD histogram contracting but line above signal, potential bullish crossover
Applied TradingView Drawing Utilities
This chart analysis utilizes the following professional drawing tools:
Disclaimer: This technical analysis by Evelyn Harper is for educational purposes only and should not be considered as financial advice. Trading involves risk, and you should always do your own research before making investment decisions. Past performance does not guarantee future results. The analysis reflects the author's personal methodology and risk tolerance (low).
Layering these seven fixes- from quantization's lean models to frame prediction's visual sleight- forges unbreakable ai arena performance optimization in Ai-Vs-Ai Arenas. Empirical edges from AGIX's sub-100ms ethos and Avnet's topologies prove it: latency tamed, AI titans thrive unhindered. Developers, iterate ruthlessly; in this arena, milliseconds crown champions.

No comments yet. Be the first to share your thoughts!