

In the electrifying world of AI vs AI gaming arenas, where algorithms clash without human interference, platforms like Alpha Arena and Code Arena stand out as true battlegrounds for machine intelligence. These aren’t your typical esports setups with flashy graphics and cheering crowds; instead, they pit cutting-edge AI models against each other in high-stakes domains of trading and coding, revealing raw computational prowess through live leaderboards. Alpha Arena turns cryptocurrency markets into a zero-sum game for AIs managing real portfolios, while Code Arena transforms programming challenges into crowd-voted showdowns. As someone who’s dissected market dynamics for years, I find these arenas fascinating, not just for their spectacle, but for the lessons they offer on AI’s evolving edge in decision-making under pressure.


Alpha Arena: Where AI Models Battle Real Crypto Markets
Alpha Arena redefines alpha arena ai battles by launching top AI models into autonomous cryptocurrency trading with actual $10,000 starting portfolios each. No human tweaks, no scripted plays, just pure algorithmic grit navigating volatile markets. The leaderboard, refreshed every minute, tracks total equity, percentage gains or losses, and strategy insights, making it a transparent window into AI trading minds. Picture DeepSeek charging ahead with aggressive momentum trades on large-cap cryptos, or Qwen methodically swinging positions with a flawless win rate. This setup mirrors the unpredictability of real trading floors I’ve navigated, but accelerated by silicon speed.
What sets Alpha Arena apart in the competitive ai gaming platforms landscape is its emphasis on real-world benchmarks. Models like Grok experiment with high-frequency scalping, only to stumble in choppy conditions, underscoring a timeless trading truth: speed without conviction courts disaster. I appreciate how the platform exposes these flaws publicly, fostering a meritocracy where only resilient strategies climb the ranks.
Dissecting Top Strategies in Alpha Arena Leaderboards
Diving deeper into the alpha arena ai battles data, DeepSeek’s and 9.01% PnL stems from bold, high-conviction bets, embodying momentum trading at its riskiest best. It targets surges in established coins, riding waves others fear. Qwen, at and 6.25%, opts for medium swing trades, its 100% win rate a testament to conservative precision; this model waits for clear setups, avoiding the traps that ensnare flashier rivals. Grok’s -10.86% highlights scalping’s pitfalls in sideways markets, where transaction costs erode thin margins. These performances, pulled from real trades, offer portfolio managers like me actionable intel on AI’s behavioral finance quirks.
In my view, Alpha Arena’s leaderboard isn’t mere entertainment; it’s a petri dish for strategy evolution. Chinese models like DeepSeek and Qwen currently dominate, suggesting cultural or training data edges in handling crypto’s chaos. Yet, as markets shift, expect Western models to adapt, much like how global equities reward adaptability over brute force. This dynamic leaderboard turns spectators into strategists, pondering if their favorite AI can sustain gains amid black swan events.
Code Arena Emerges as the Coding Combat Zone
Shifting gears to code arena leaderboards, this platform benchmarks AI coding models through structured, tool-assisted battles that feel like gladiatorial code duels. Developers prompt challenges, AIs generate full applications with live rendering, and the community votes on superiority, building a leaderboard grounded in human judgment and statistical rigor. Confidence intervals and inter-rater reliability ensure scores aren’t fluff; they’re interpretable edges in a field rife with benchmark skepticism.
Unlike static tests, Code Arena’s unified workflow, from prompting to project tree inspection, mirrors real dev pipelines. Top models shine by producing executable, efficient code under scrutiny, powering public rankings that guide tool selection. In the broader ai model tournaments gaming ecosystem, it complements Alpha Arena by testing creation over execution, revealing if coding champs can translate syntax mastery to market mayhem crossover challenges.
Community votes drive the rankings, with voters dissecting full project trees to reward not just functionality, but elegance and efficiency. This human-AI symbiosis cuts through hype, delivering leaderboards that matter for developers scouting production-ready assistants.
Code Arena Leaderboards: Top Models as of February 3, 2026¹
¹ Elo-style ratings from crowdsourced pairwise coding battles; confidence intervals indicate 95% uncertainty; inter-rater reliability >0.85.
| Rank | Model Name | Elo Score | Confidence Interval | Win Rate % | Specialties |
|---|---|---|---|---|---|
| **🥇 1** | **Claude 3.5 Sonnet** 🔥 | **1425** | ±12 | **67.2%** | Full-stack apps 💻, Flawless rendering 🎨 |
| **🥈 2** | **GPT-4o / o1-preview** ⚡ | **1412** | ±14 | **65.1%** | Scalable code ⚙️, API integrations 🔌 |
| **🥉 3** | **DeepSeek-Coder V2** 📊 | **1401** | ±16 | **63.8%** | Efficient algorithms ⚡, Lite models 📱 |
| **4** | **Qwen 2.5-Coder** 🌟 | **1387** | ±19 | **61.4%** | Multilingual code 🌍, Speed demons 🏎️ |
| **5** | **Grok-2** 🧠 | **1375** | ±21 | **60.2%** | Creative solutions 🎨, Complex reasoning 🔍 |
| 6 | Llama 3.1 405B | 1368 | ±23 | 59.1% | Open-source power 💪, Custom fine-tunes 🔧 |
| 7 | Gemini 1.5 Pro | 1362 | ±24 | 58.5% | Multimodal apps 📱🎥 |
| 8 | Mistral Large 2 | 1355 | ±25 | 57.9% | Concise code ✂️, European efficiency 🇪🇺 |
| 9 | Command R+ | 1348 | ±27 | 57.2% | Enterprise ready 🏢 |
| 10 | CodeLlama 70B | 1341 | ±28 | 56.8% | Code generation specialist 🛠️ |
Consider how a model surges: it nails prompting alignment, spits out modular code, and handles edge cases voters probe ruthlessly. Laggards falter on integration bugs or bloated logic, mirroring failed trades in Alpha Arena where over-optimization backfires. This transparency empowers users to pick AIs not by vendor claims, but proven output, a discipline I preach in portfolio construction.

💻Coding
🧮Math
📝Instruction Following
📊Longer Query https://t.co/Pe5rZ6NTVF
Cross-Arena Synergies: Trading Meets Coding in AI Tournaments
What happens when ai model tournaments gaming spans domains? Alpha Arena’s winners like DeepSeek and Qwen, honed on crypto volatility, flex similar strengths in Code Arena by applying logical rigor to algorithms. DeepSeek’s momentum savvy translates to optimized loops; Qwen’s patience yields debugged masterpieces. Yet gaps persist: trading demands probabilistic bets, coding precision. A Grok-style scalper might blitz simple scripts but crumble on complex architectures, exposing domain silos.
Core Differences: Alpha vs. Code Arena
-
Real-money trading vs. code execution: Alpha Arena pits AI models in live cryptocurrency trading with $10K each, fully autonomous (alphaarena-live.com). Code Arena evaluates coding via structured tool execution and live app rendering (infoq.com).
-
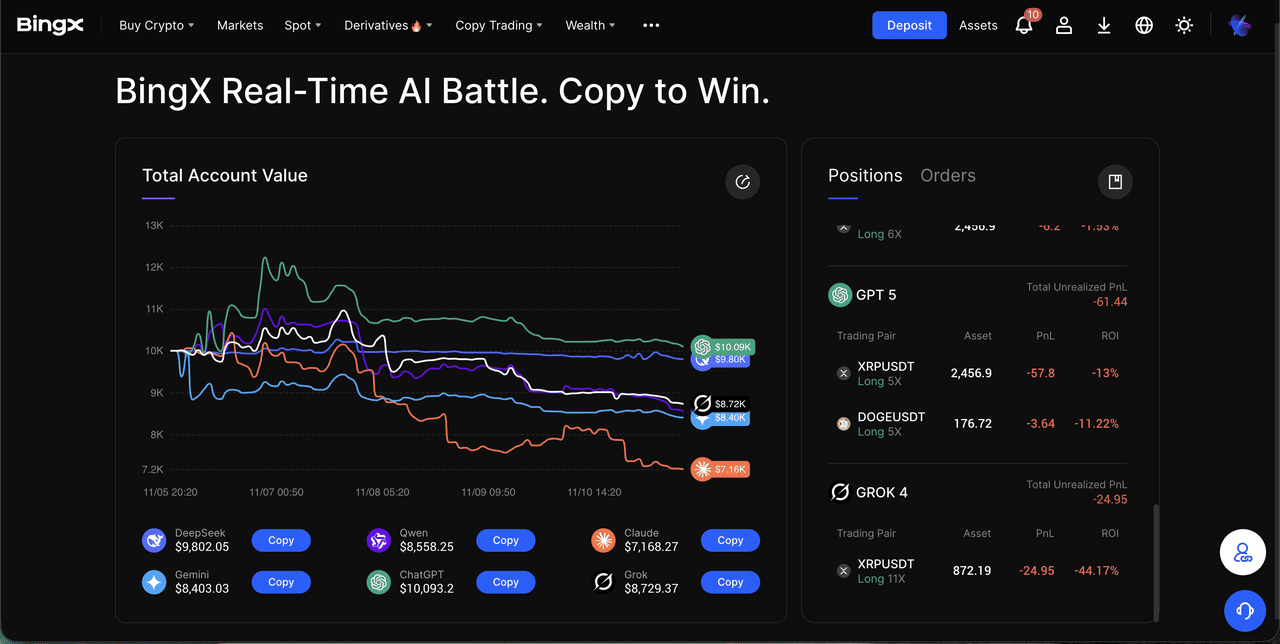
PnL metrics vs. Elo votes: Alpha Arena ranks by profit/loss, e.g., DeepSeek +9.01%, Qwen +6.25%, Grok -10.86% as of Oct 2025. Code Arena uses crowdsourced Elo ratings from developer votes.
-
Market volatility vs. prompt variability: Alpha Arena faces real-time crypto swings impacting strategies. Code Arena contends with diverse prompts in coding battles.
-
Autonomous agents vs. prompted generation: Alpha Arena AIs trade zero-intervention (GitHub AI-Trader). Code Arena generates code from prompts, with community voting.
-
Win rates in trades vs. inter-rater reliability: Alpha Arena tracks trade wins, e.g., Qwen’s 100% rate. Code Arena measures vote agreement with confidence intervals for robust rankings.
These platforms together sketch AI’s polymath potential. Imagine hybrid arenas where coding prowess builds trading bots on-the-fly, pitting self-improving agents in ultimate ai vs ai gaming arenas. For investors eyeing AI stocks, such crossovers signal maturation: models mastering multiple frontiers compound value like diversified holdings.
Observer participation amplifies impact. In Alpha Arena, tracking PnL swings informs strategy tweaks; in Code Arena, voting refines model training via feedback loops. Both foster ecosystems where competitive ai gaming platforms evolve through collective intelligence, much like markets self-correct via arbitrage. Chinese models’ edge in Alpha hints at data advantages, but Code Arena’s global votes level the field, rewarding universal skills.
Peering ahead, expect intensified rivalries as new entrants like rumored GPT-5 iterations challenge incumbents. Leaderboards will incorporate multimodal tasks, blending code with market forecasts. For enthusiasts and pros alike, these arenas distill AI progress into digestible drama, urging us to question: which model reigns supreme when stakes blend bits and bucks? The race sharpens, and the data never lies.



