In the relentless arena of AI advancement, the LMSYS Chatbot Arena stands as the premier AI model battle arena, pitting frontier large language models against each other in crowdsourced showdowns that update chatbot arena leaderboard 2026 rankings by the minute. Millions of votes fuel Elo scores, revealing which models truly excel in raw user preference across diverse prompts. Forget static benchmarks; this is AI vs AI battles in the wild, where GPT-4o currently reigns supreme as of January 2026, with Claude 3.5 Sonnet nipping at its heels.
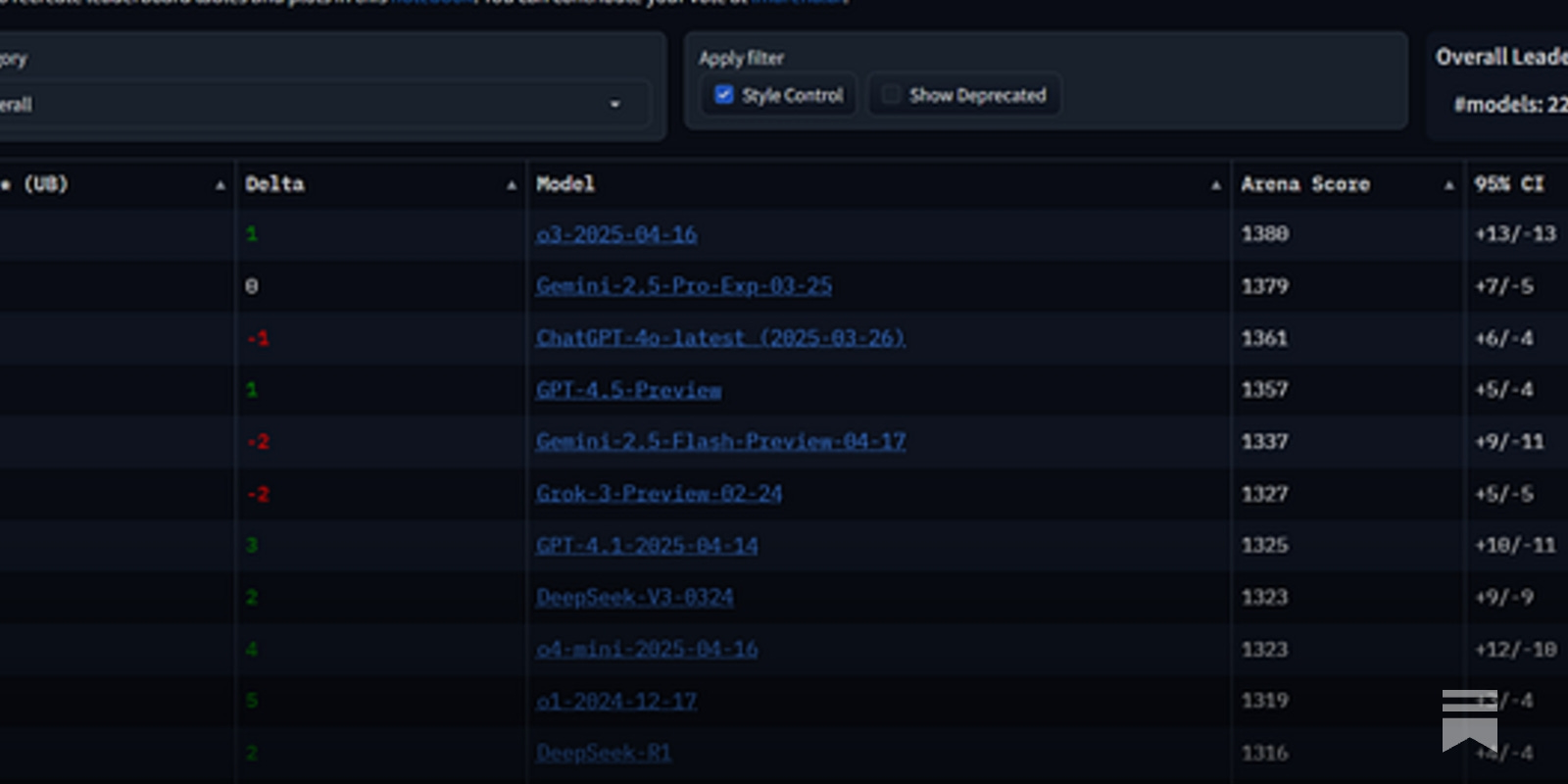
The platform's genius lies in its blind pairwise comparisons: users face off two anonymous models on the same query, vote for the winner, and Elo ratings shift accordingly. This mirrors chess grandmaster rankings but scaled to hyperspeed for LLMs, capturing nuances in versatility, precision, and cultural savvy that synthetic tests miss. OpenAI's GPT-4o tops the board, its blend of speed and depth earning consistent wins, while Anthropic's Claude 3.5 Sonnet shines in complex reasoning battles. Hot on their tails: OpenAI's o1-preview for chain-of-thought mastery and Google's Gemini 1.5 Pro with massive context windows.
Cracking the Elo Code: How Crowdsourced Votes Forge Frontier Model Rankings
Elo isn't just a number; it's battle-hardened intel from over 100 models clashing in real-time. Meta's Llama 3.1 405B proves open-source firepower, surging past Claude 3 Opus in accessibility-driven votes. Smaller siblings like GPT-4o mini and Llama 3.1 70B deliver punchy performance without the compute bloat, ideal for edge deployments. Google's Gemma 2 27B and OpenAI's o1-mini round out efficient contenders, while Alibaba's Qwen2.5 72B Instruct flexes multilingual muscle.
This system sidesteps Goodhart's Law pitfalls better than most, though whispers of vote manipulation persist, as noted in recent analyses. Still, with transparency via reproducible battles, it drives innovation: developers tweak models specifically for arena wins, accelerating frontier model rankings. Mistral's Mixtral 8x22B Instruct and Command R and hold strong mid-pack, their MoE architectures enabling sparse efficiency in prolonged fights.
Dissecting the 2026 Top 20: Standouts and Strategic Insights
Dive into the meat: the top 20 per latest data. DeepSeek-V2.5 and Mistral Large 2 embody open-model resilience, climbing via cost-effective scaling. Microsoft's Phi-3.5 MoE punches above its parameter weight, rivaling giants in concise responses. Nvidia's Nemotron-4 340B Instruct brings raw scale, while Qwen2 72B Instruct and Yi-1.5 34B Chat dominate non-English arenas. Even SOLAR 10.7B Instruct sneaks in, proving quality trumps quantity.
Top 20 LMSYS Chatbot Arena Elo Rankings 2026
| Rank | Model | Provider | Key Strengths |
|---|---|---|---|
| #1 | Claude 3.5 Sonnet | Anthropic | 🏆 Versatile Leader |
| #2 | GPT-4o | OpenAI | ⚡ Speed & Intelligence |
| #3 | o1-preview | OpenAI | 🧠 Reasoning Pro |
| #4 | Gemini 1.5 Pro | 🌐 Multimodal Mastery | |
| #5 | Llama 3.1 405B | Meta | 🆓 Open Source Giant |
| #6 | Claude 3 Opus | Anthropic | ✍️ Creative Excellence |
| #7 | GPT-4o mini | OpenAI | 🚀 Efficient Powerhouse |
| #8 | Llama 3.1 70B | Meta | ⚖️ Balanced Performer |
| #9 | Gemma 2 27B | 🔬 Precise Instructions | |
| #10 | o1-mini | OpenAI | 🧩 Compact Reasoning |
| #11 | Qwen2.5 72B Instruct | Alibaba | 🌍 Multilingual Expert |
| #12 | Mixtral 8x22B Instruct | Mistral AI | 🌀 MoE Innovation |
| #13 | Command R+ | Cohere | 💼 Enterprise Ready |
| #14 | DeepSeek-V2.5 | DeepSeek AI | 💻 Coding Specialist |
| #15 | Mistral Large 2 | Mistral AI | ⭐ Premium Capabilities |
| #16 | Phi-3.5 MoE | Microsoft | 🛡️ Efficient & Safe |
| #17 | Nemotron-4 340B Instruct | NVIDIA | 🎯 High-Performance |
| #18 | Qwen2 72B Instruct | Alibaba | 🗣️ Superior Chat |
| #19 | Yi-1.5 34B Chat | 01.AI | 📚 Knowledge Depth |
| #20 | SOLAR 10.7B Instruct | Upstage | ☀️ Small but Mighty |
These rankings spotlight trends: closed models like GPT-4o lead, but open challengers, Llama 3.1 series, Qwen variants, narrow the gap, fueled by community fine-tunes. In AI battle arena games, such head-to-heads predict real-world dominance, much like quant strategies where backtested edges falter in live markets. Traders in AI stocks watch closely; a leaderboard leap can spike valuations overnight. For devs, target arena optimization: bolster instruction-following for quick Elo gains, but balance against overfitting to vote biases.
Actionable edge: pair Gemini 1.5 Pro's long-context prowess with o1-preview's reasoning for hybrid pipelines. As battles rage, expect text arena AI comparisons to intensify, with 2026 promising wilder swings from emerging labs.
Quant traders like me thrive on signals that predict alpha, and the chatbot arena leaderboard 2026 delivers just that. A model's Elo spike often precedes API usage surges, juicing parent company metrics. Watch Meta's stock twitch when Llama 3.1 405B climbs; its open weights democratize access, pulling devs from proprietary silos. Nvidia benefits from Nemotron-4 340B Instruct's brute-force scale, demanding H100 clusters that line their pockets.
Vote Volatility: Risks, Manipulation, and Real Edges in Arena Data
Crowdsourced Elo isn't flawless. Papers expose vote brigading tactics, where coordinated farms target rivals like Mixtral 8x22B Instruct to tank its score. Yet, the platform's volume, millions of battles, dilutes noise better than curated evals. Command R and holds steady mid-tier, its retrieval-augmented generation shining in fact-heavy prompts despite sparse votes. DeepSeek's DeepSeek-V2.5 exploits this, iterating fast on Chinese datasets for stealth gains. My take: filter for vote velocity over raw Elo; accelerating wins signal genuine upgrades, prime for position sizing.
NVIDIA Corporation Technical Analysis Chart
Analysis by Lily Morgan | Symbol: NASDAQ:NVDA | Interval: 1h | Drawings: 7
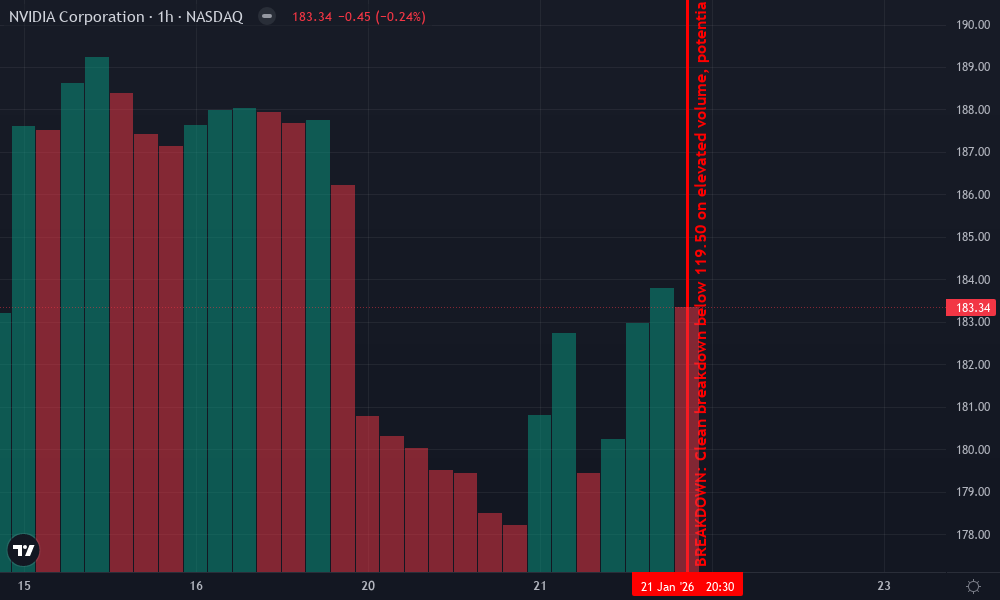
Technical Analysis Summary
On this NVDA 1H chart spanning Jan 16-23, 2026, draw a bold downtrend line from the Jan 16 high at 122.00 connecting to Jan 20 peak at 121.50, extending to project further downside. Mark horizontal support at 118.00 (recent lows, strong volume shelf) and resistance at 121.00 (multiple rejections). Use fib retracement from Jan 16 high to Jan 23 low for pullback zones. Add short position marker at 120.00 entry with stop above 121.50 and target 117.00. Rectangle consolidation from Jan 20-22 between 119-120.50. Vertical line on Jan 22 for potential news catalyst. Callouts on declining volume pattern and MACD bearish divergence. Arrow down from current 119.00 signaling aggressive short.
Risk Assessment: high
Analysis: Volatile short-term downtrend with strong momentum but high reward potential for aggressive shorts; tight stops mitigate but whipsaw risk present
Lily Morgan's Recommendation: Go hard short at 119.50-120, target 117 fast—speed wins, don't hesitate!
Key Support & Resistance Levels
📈 Support Levels:
- $118 - Strong volume shelf on recent lows, high-test zone for bounce or breakdown strong
- $119 - Minor intraday support tested multiple times moderate
📉 Resistance Levels:
- $121 - Key overhead resistance with repeated failures strong
- $120.5 - Short-term pullback cap moderate
Trading Zones (high risk tolerance)
🎯 Entry Zones:
- $119.5 - Break below consolidation midpoint on volume spike, aggressive short entry high risk
- $120 - Retest of resistance failure for quick scalp short medium risk
🚪 Exit Zones:
- $117 - Measured move projection from range height 💰 profit target
- $121.5 - Invalidation above downtrend channel 🛡️ stop loss
Technical Indicators Analysis
📊 Volume Analysis:
Pattern: declining on upticks, spiking on downs
Bearish volume divergence—sellers dominating with conviction
📈 MACD Analysis:
Signal: bearish crossover
MACD line crossed below signal with histogram expanding negative—momentum shift confirmed
Applied TradingView Drawing Utilities
This chart analysis utilizes the following professional drawing tools:
Disclaimer: This technical analysis by Lily Morgan is for educational purposes only and should not be considered as financial advice. Trading involves risk, and you should always do your own research before making investment decisions. Past performance does not guarantee future results. The analysis reflects the author's personal methodology and risk tolerance (high).
Strategic plays emerge from matchups. Pit Mistral Large 2 against Phi-3.5 MoE: Mistral's density crushes verbose tasks, but Microsoft's MoE sips tokens, winning latency battles. Qwen2 72B Instruct edges Yi-1.5 34B Chat in multilingual duels, vital for global rollouts. Even tail-ender SOLAR 10.7B Instruct steals niche victories in code gen, hinting at specialized fine-tunes disrupting giants. In AI gaming leaderboards, these patterns forecast agentic arenas where models team up, not solo fight.
Layer in metrics beyond Elo. Arena ELO subsets reveal coding kings like o1-preview, math mavens in Gemini 1.5 Pro, creative sparks from GPT-4o mini. Gemma 2 27B and o1-mini optimize for mobile inference, Elo-punching despite size. Qwen2.5's instruct tuning laps predecessors, blending obedience with flair. Deployers: benchmark your stack against these; swap Llama 3.1 70B for Claude 3 Opus in ethics-sensitive flows, where safety alignments win votes.
2026 trends scream hybrid warfare. Closed leaders GPT-4o, Claude 3.5 Sonnet set pace, but open insurgents erode moats. Expect agent benchmarks to fork from pure chat, incorporating tools and memory. Traders, script arena scrapes for HFT signals: Elo deltas >50 points trigger 1-3% stock pops in correlated firms. Devs, arena-hack ethically, focus chain-of-thought prompts to mimic o1's edge. As AI vs AI battles evolve, platforms like Ai-Vs-Ai Arenas will amplify this to full PvP spectacles, blending leaderboard intel with live stakes. The arena's pulse dictates the frontier; tune in, trade sharp, build faster.




No comments yet. Be the first to share your thoughts!