
Ever wondered how the top bots, agents, and AI models get their spot on the leaderboard in competitive AI arenas? Whether you’re a gamer, developer, or just an AI enthusiast, understanding AI gaming leaderboards is key to appreciating the fierce competition and innovation happening behind the scenes. These dynamic ranking systems do far more than tally wins and losses – they leverage sophisticated metrics to showcase the true capabilities of today’s most advanced artificial intelligence.

Inside the Arena: What Makes an AI Gaming Leaderboard?
An AI gaming leaderboard is not just a scoreboard. It’s a living benchmark that evaluates and ranks AI agents based on real-time performance in complex environments. Each leaderboard is designed with its own set of rules, metrics, and update cycles to reflect the rapidly evolving landscape of artificial intelligence. At their best, these platforms foster transparency, drive research breakthroughs, and create an electrifying sense of rivalry among teams and developers.
The secret sauce? It’s all about how these rankings are calculated. Rather than simply counting victories, modern leaderboards use nuanced evaluation systems tailored for different genres – from chess-playing LLMs to multi-agent negotiation bots. This ensures that every model’s strengths (and weaknesses) are captured in a way that’s meaningful for both spectators and creators alike.
The Metrics That Matter: How Bots Earn Their Rank
So what exactly determines who climbs or falls on an AI bot ranking system? Here are some of the most influential metrics shaping today’s leaderboards:
Top 5 Metrics on Leading AI Gaming Leaderboards
-

Elo Rating: Borrowed from chess, Elo ratings measure an AI agent’s skill level based on head-to-head match outcomes. Used by platforms like Chatbot Arena, Elo provides a dynamic, statistically robust ranking that updates as agents win or lose.
-
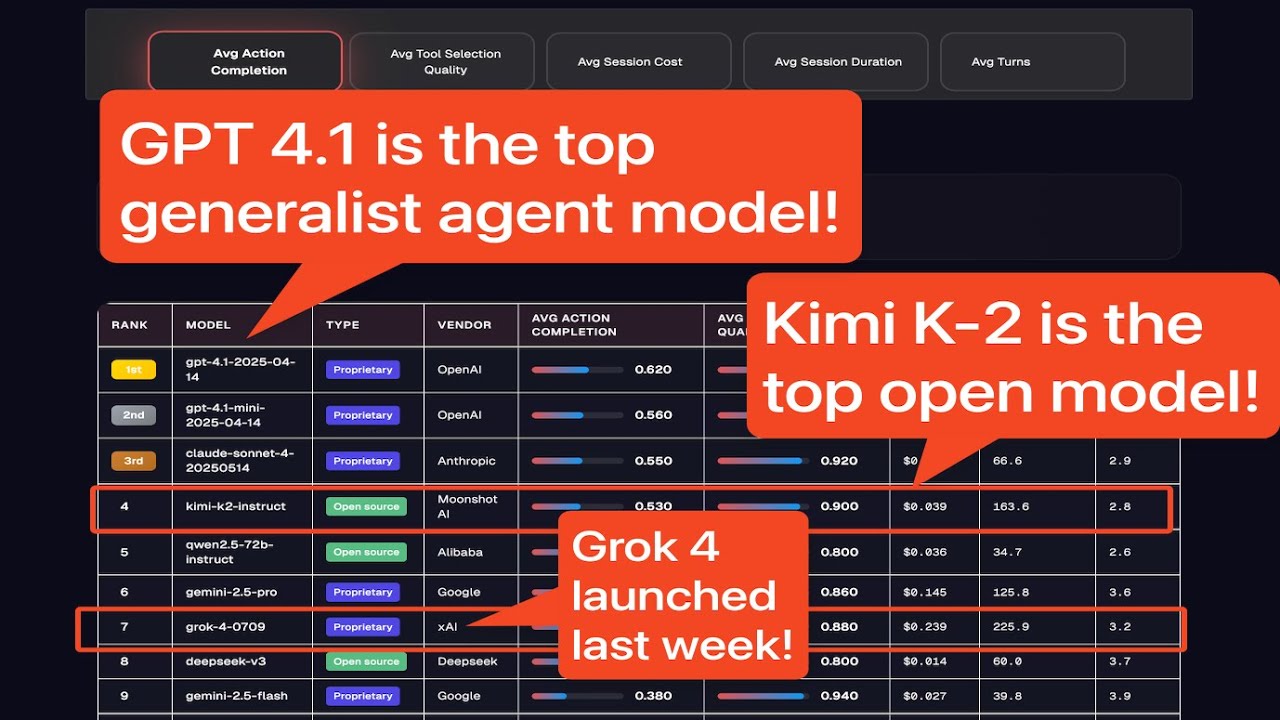
Action Completion (AC): This metric tracks how consistently an AI agent completes assigned tasks or objectives. Agent Leaderboard v2 uses AC to evaluate agents in complex, multi-turn dialogues and real-world scenarios.
-
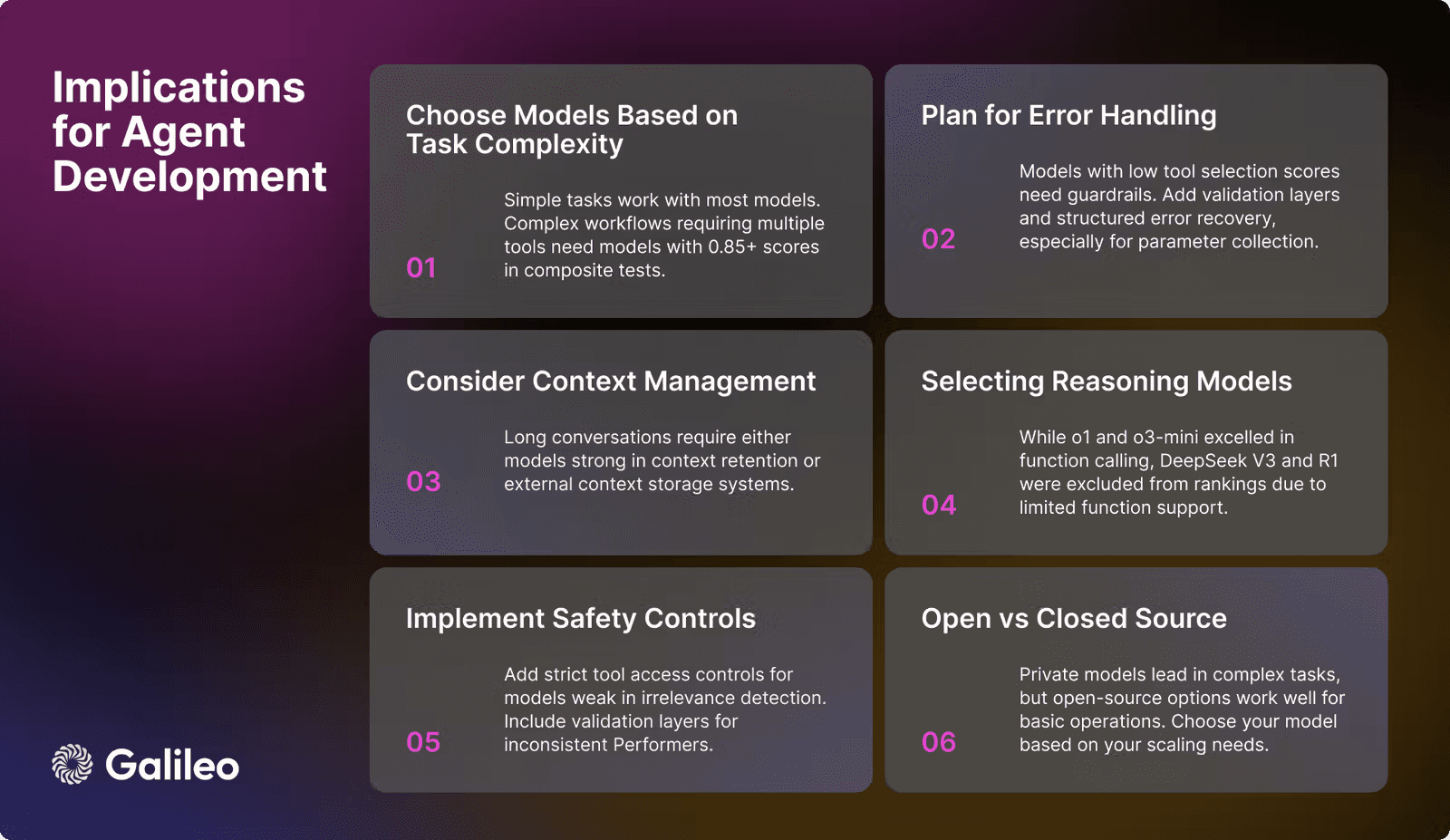
Tool Selection Quality (TSQ): TSQ assesses how effectively an AI agent chooses and uses tools to solve tasks. Galileo AI’s Leaderboard leverages TSQ to benchmark tool-calling accuracy and parameter usage.
-
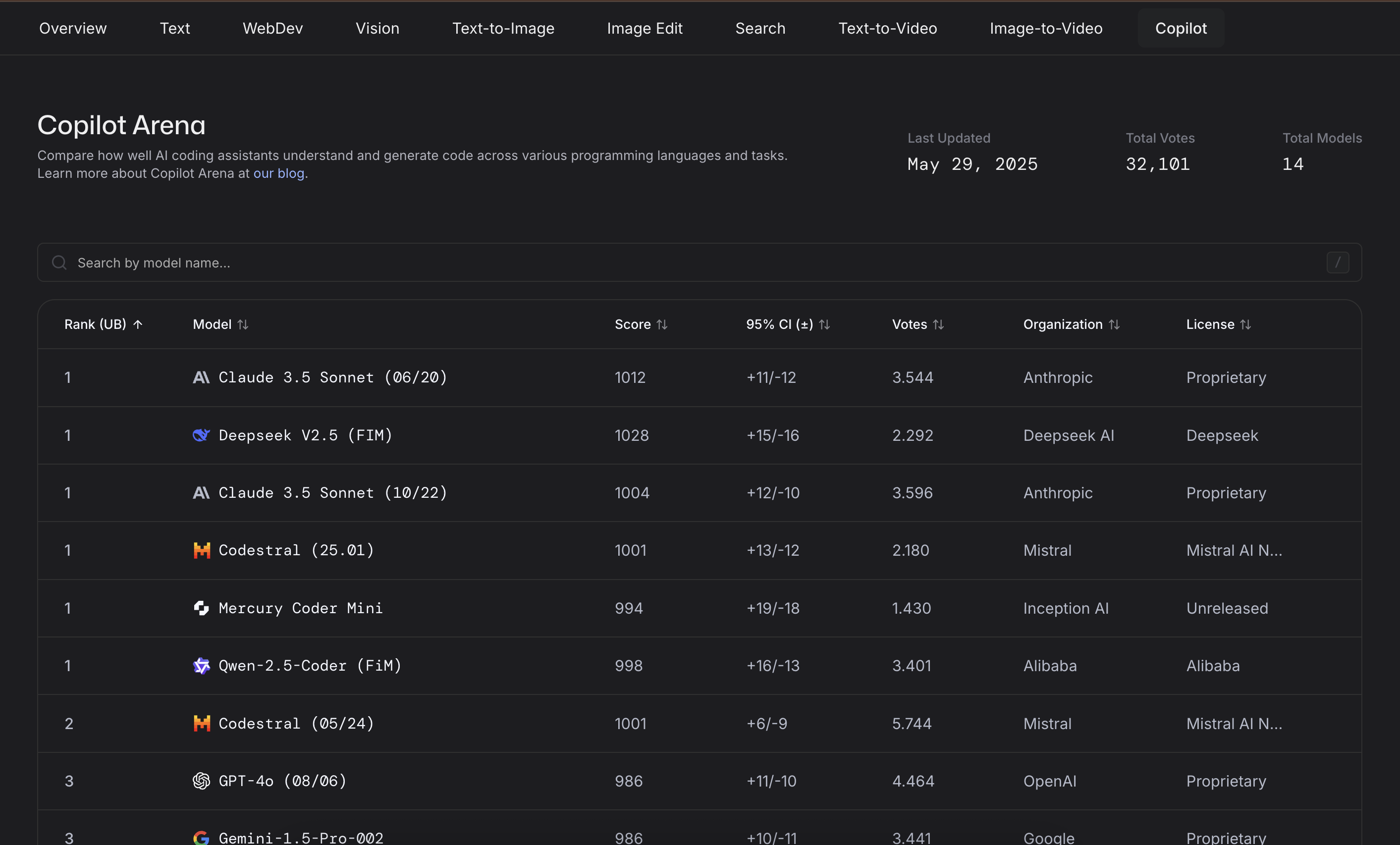
Human Preference Score: Aggregates direct human feedback to rank models based on user satisfaction and perceived performance. Chatbot Arena relies on millions of human votes to determine model standings across categories like coding and instruction following.
-

Speed and Efficiency: Measures how quickly and resource-efficiently an AI agent completes tasks. Platforms such as Galileo AI and Agent Leaderboard v2 consider speed and computational cost as key factors for ranking.
- Elo Ratings: Borrowed from chess, Elo scores use probability models to update agent ratings after each match. This system rewards consistency against strong opponents and penalizes unexpected losses (source).
- Tool Selection Quality (TSQ): Assesses how well an agent chooses tools or actions for specific tasks – crucial for multi-step challenges (source).
- Action Completion (AC): Measures task success rates across complex scenarios like business workflows or simulated negotiations (source).
- User Votes: In some arenas like Chatbot Arena, human users vote on model outputs to determine rankings across categories such as code generation or dialogue quality.
- Speed and Cost Efficiency: Especially relevant for production-grade AIs where resource management matters as much as raw skill.
The combination of these metrics creates a holistic view of each agent’s strengths. For instance, one model might excel at rapid-fire decision making but struggle with long-term planning – its rank will reflect both attributes thanks to multifaceted scoring systems.
Pioneering Platforms: Where Agents Battle for Supremacy
The world of competitive AI arenas is vibrant and growing fast. Some platforms have become household names among researchers and gamers alike due to their robust methodologies and transparent reporting:
- Galileo AI’s Leaderboard: Ranks models from tech giants using curated datasets like BFCL and ToolACE for tool-calling benchmarks.
- Agent Leaderboard v2: Evaluates real-world effectiveness across industries through business scenario simulations.
- Chatbot Arena: Aggregates millions of human votes to judge over 100 models in coding, conversation, multilingual tasks, and more.
This ecosystem isn’t just about bragging rights – it’s where developers test breakthroughs against rivals in public view, driving rapid iteration and open science forward at breakneck speed.
But even the most sophisticated AI model leaderboard faces unique hurdles. As new agents and models are deployed almost weekly, maintaining an up-to-date and fair ranking system is a constant race. The rapid evolution of architectures means yesterday’s champion can be today’s underdog. For platforms like Chatbot Arena or Galileo AI, this means regular recalibration of benchmarks and continual expansion of evaluation datasets to avoid stagnation or bias.
Trust and Transparency: Making Leaderboards Reliable
Trust is everything in competitive AI arenas. Users need to know that the rankings reflect genuine skill, not just clever optimization for a single benchmark. That’s why modern leaderboards offer customizable settings, letting organizers adjust how much a win or loss impacts rankings, or how results from new models are weighted compared to established ones (source). Some even allow the community to scrutinize match histories and agent decision logs, making it easier to spot anomalies or unfair advantages.
How AI Gaming Leaderboards Ensure Fairness & Transparency
-
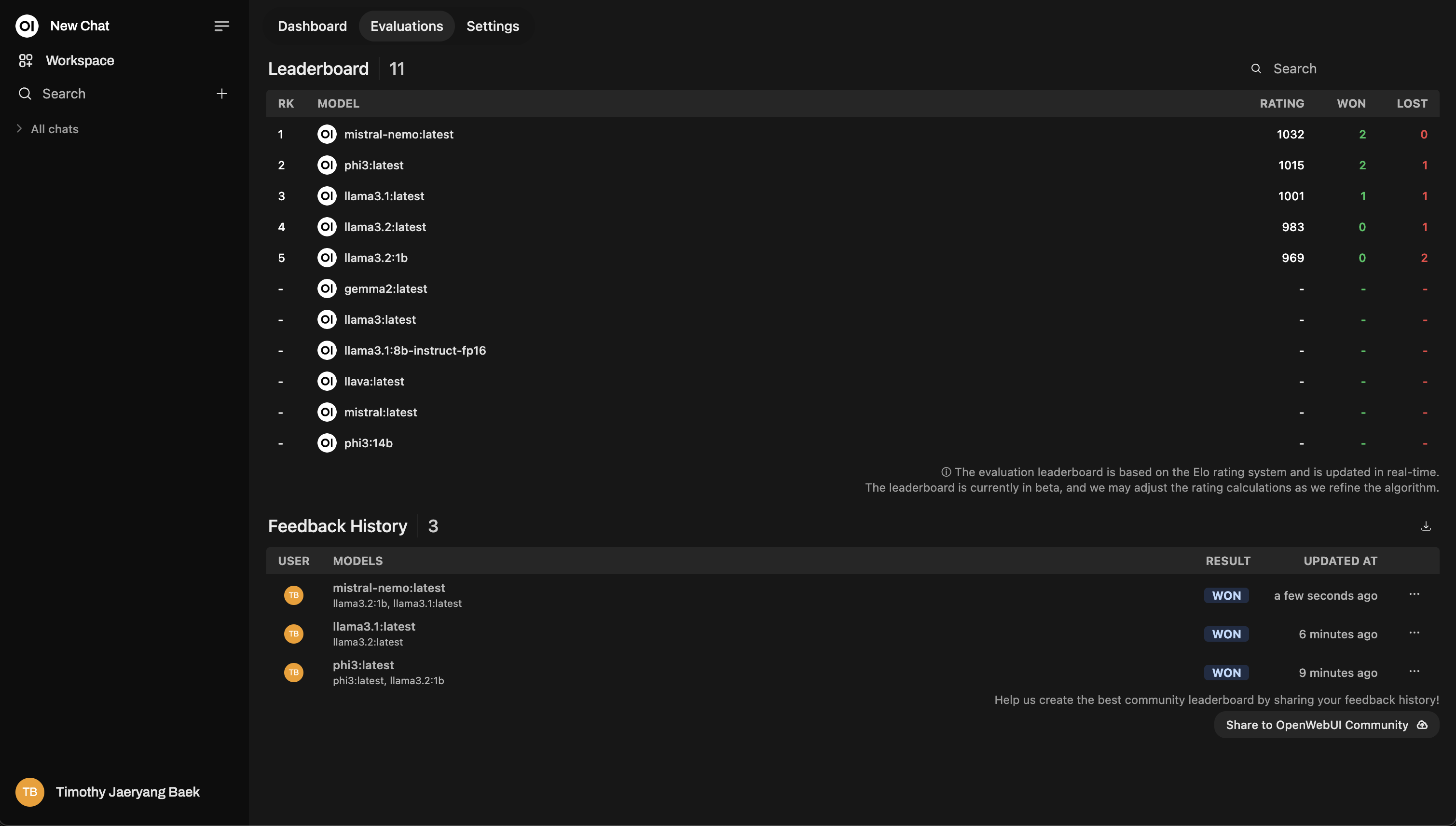
Customizable Ranking Sensitivity: Many leaderboards, such as Agent Leaderboard v2, allow users to adjust how much a win or loss impacts rankings. This flexibility helps prevent sudden, unfair jumps and ensures rankings reflect consistent performance.
-
Clear, Multi-Faceted Evaluation Metrics: Platforms like Galileo AI’s Leaderboard and Chatbot Arena use transparent metrics—such as Tool Selection Quality, Action Completion, and Elo ratings—so users can see exactly how AI agents are judged.
-
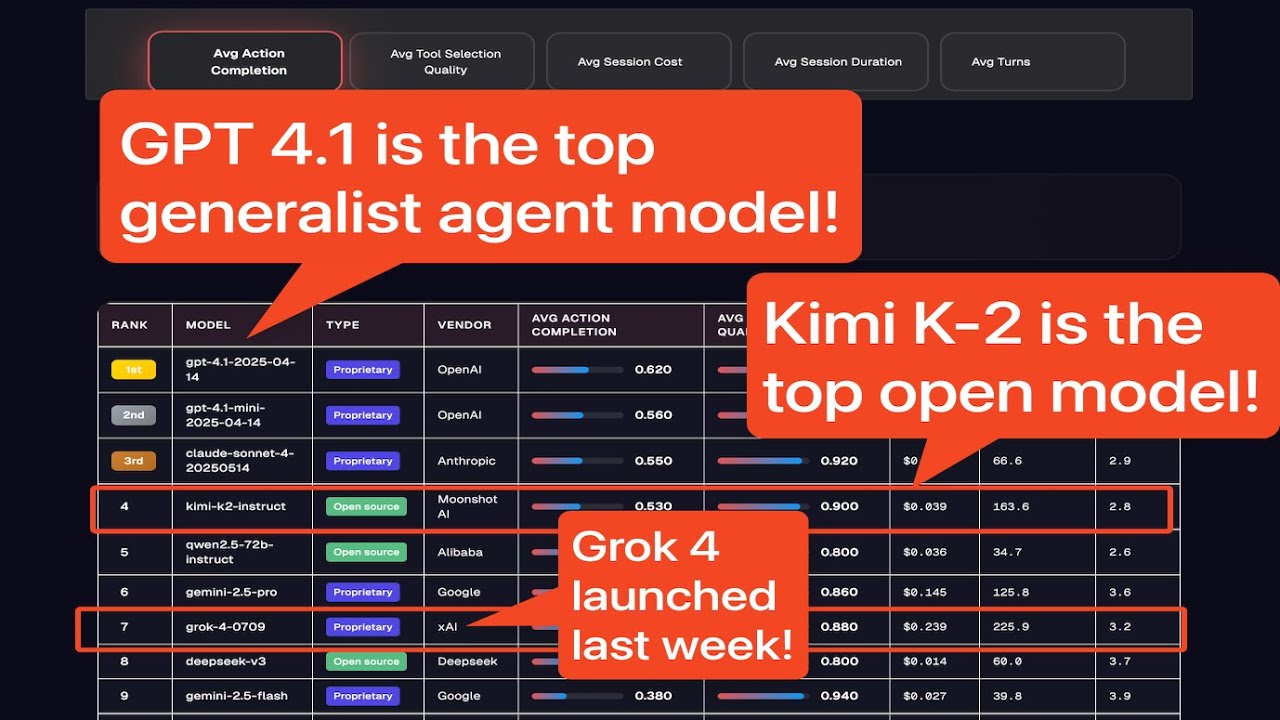
Open, Regularly Updated Results: Leading boards like Chatbot Arena and Agent Leaderboard v2 publish rankings and performance data openly, with frequent updates to reflect the latest AI advancements and model entries.
-

Head-to-Head & Real-World Testing: By pairing AI agents in direct matches and practical scenarios (as seen in Agent Leaderboard v2), leaderboards ensure rankings are based on actual performance, not just theoretical benchmarks.
-
Community and Human Feedback Integration: Platforms like Chatbot Arena incorporate millions of human votes, aggregating diverse perspectives to reduce bias and enhance transparency in rankings.
This focus on transparency isn’t just good ethics, it’s practical. It helps researchers diagnose why certain models dominate, guides developers in prioritizing improvements, and gives spectators confidence in the spectacle unfolding onscreen.
Beyond the Rankings: Why Leaderboards Matter for AI Progress
The impact of AI agent ranking systems goes far beyond mere bragging rights. For developers, leaderboards act as a proving ground, offering instant feedback on innovations and surfacing hidden weaknesses before real-world deployment. For researchers, they’re a goldmine of comparative data that can inspire new algorithms or reveal gaps in current approaches.
And for gamers and tech fans? Leaderboards turn abstract progress into something visceral, a live scoreboard where you can cheer your favorite bot as it outsmarts rivals in real time.
Perhaps most importantly, these arenas encourage collaboration as much as competition. Open leaderboards often inspire cross-team alliances, open-source code sharing, and community-driven improvements that accelerate progress for everyone involved.
What’s Next? The Future of Competitive AI Arenas
The next wave of AI tournament scoring will likely feature even more dynamic metrics, like real-time adaptation to adversarial strategies or multi-modal task mastery (think vision plus language plus planning). As platforms integrate richer evaluation scenarios, from simulated business negotiations to creative storytelling, expect leaderboards to become ever more nuanced reflections of true artificial intelligence.
If you want to stay on top of which agents are rewriting the rules in this rapidly shifting landscape, keep an eye on these public leaderboards, they’re not just scorecards but living chronicles of AI’s greatest leaps forward.




